
توضیحات
کنترل بهینه مبتنی بر یادگیری تقویتی برای سیستم غیرخطی محدود از طریق یک تبدیل جدید وابسته به حالت
عنوان اصلی مقاله:
Reinforcement Learning based Optimal Control for Constrained Nonlinear System via A Novel State-Dependent Transformation
شبیه سازی در محیط ام فایل متلب انجام شده است.
بیشتر بدانیم:
در این مقاله، یک روش کنترل بهینه مبتنی بر یادگیری تقویتی برای سیستمهای غیرخطی با محدودیت ورودی ارائه شده است. این روش از یک تابع تبدیل غیرخطی وابسته به حالت جدید استفاده میکند که سیستمهای غیرخطی با محدودیت حالت را به یک سیستم جدید با محدودیت ورودی تبدیل میکند. سپس از تکنیک بهینهسازی بازگشتی برای توسعه کنترلکننده بهینه برای سیستم جدید استفاده میشود تا سیگنال مرجع مورد نظر را بدون شرایط امکانپذیری دنبال کند.
روش تبدیل وابسته به حالت:
در یادگیری تقویتی، **روش تبدیل وابسته به حالت** یکی از روشهای مورد استفاده است. این روش برای مسائل کنترل بهینه در سیستمهای غیرخطی با محدودیت ورودی مورد استفاده قرار میگیرد.
در این روش، از یک تابع تبدیل غیرخطی وابسته به حالت جدید استفاده میشود. این تابع تبدیل، سیستمهای غیرخطی با محدودیت حالت را به یک سیستم جدید با محدودیت ورودی تبدیل میکند. سپس از تکنیکهای بهینهسازی بازگشتی مانند مونت کارلو یا یادگیری تفاوت زمانی (TD) برای توسعه کنترلکننده بهینه برای سیستم جدید استفاده میشود. این کنترلکننده به عامل اجازه میدهد تا سیگنال مرجع مورد نظر را بدون شرایط امکانپذیری دنبال کند.
به طور خلاصه، روش تبدیل وابسته به حالت در یادگیری تقویتی، یک راهحل برای کنترل سیستمهای غیرخطی با محدودیت ورودی است که از تابع تبدیل و تکنیکهای بهینهسازی استفاده میکند.
توضیحات پروژه کنترل بهینه مبتنی بر یادگیری تقویتی
شبیهسازی کنترل تطبیقی مبتنی بر یادگیری تقویتی برای سیستمهای غیرخطی با قیود انجام شده است.
مقدمه
در این گزارش، دو مثال عددی از مقالهی “Reinforcement Learning based Optimal Control for Constrained Nonlinear System via A Novel State-Dependent Transformation” پیادهسازی و تحلیل شده است. هدف از این شبیهسازی، ارزیابی عملکرد کنترلر تطبیقی پیشنهادی بر اساس تبدیل وابسته به حالت (NSDF) در حضور قیود و دینامیکهای غیرخطی است.
مثال اول: سیستم غیرخطی درجه دوم با دو حالت
مشخصات سیستم
یک سیستم غیرخطی با دو حالت در نظر گرفته شده که توسط کنترلر تطبیقی پیشنهادی در مقاله کنترل میشود. محدودیتهای ورودی و حالت نیز لحاظ شدهاند.
توضیح کد اصلی شبیهسازی:
- init شامل مقدار اولیه برای متغیرهای حالت و وزنهای شبکه عصبی است.
- حل عددی معادلات دینامیکی را با استفاده از تابع system_equations انجام میدهد.
- دادههای خروجی in به متغیرهای مربوطه تقسیم میشوند.
- شکلهای ۲ تا ۶ رفتار سیستم، سیگنالهای کنترلی، خطای ردیابی و روند همگرایی وزنهای شبکه عصبی را نمایش میدهند.
توضیح تابع system_equations:
- تعریف ضرایب کنترل و یادگیری.
- تبدیل مقادیر حالت و سیگنال مرجع به فضای جدید توسط NSDF.
- تخمین کنترلرهای مجازی و اصلی.
- تعریف معادلات دینامیکی سیستم طبق معادله (86) مقاله.
- بهروزرسانی وزنهای شبکههای عصبی طبق معادله (24).
- خروجی نهایی شامل مشتق حالات و وزنها و کنترلرها است.
مثال دوم: سیستم سهحالتِ مکانیکی الکترومغناطیسی (مشابه بازوی رباتیک)
مشخصات سیستم
این سیستم شامل سه متغیر حالت و مدلسازی دقیق از پارامترهای فیزیکی مانند جرم، گشتاور، مقاومت، القاگر و … است. کنترل بهصورت سه مرحلهای انجام شده و قیود در سطوح مختلف اعمال شدهاند.
توضیح کد اصلی شبیهسازی:
- مقدار اولیه تمام وزنها و حالات در init تعریف شدهاند.
- حل معادلات با.. برای بازه زمانی 0 تا 30 ثانیه.
- تجزیه ماتریس in برای استخراج حالات و وزنها.
- رسم شکلهای ۷ تا ۱۰ شامل خروجی سیستم، ردیابی مرجع، خطا، و سیگنالهای کنترلی.
توضیح تابع system_equations:
- تعریف ضرایب کنترلی برای هر مرحله از کنترل.
- تعریف پارامترهای فیزیکی سیستم از جدول ۲ مقاله.
- اعمال تبدیل NSDF به هر سه حالت و سیگنال مرجع.
- محاسبه کنترلرهای مجازی و واقعی بر اساس ساختار یادگیری تقویتی.
- تعریف معادلات دینامیکی سیستم (معادله 86).
- بهروزرسانی وزنهای شبکه عصبی با استفاده از قوانین پیشنهادی.
نتیجهگیری
نتایج شبیهسازی نشان میدهند که الگوریتم کنترل تطبیقی پیشنهادی بر مبنای NSDF و شبکههای عصبی قادر به دنبال کردن سیگنال مرجع با دقت بالا، حفظ پایداری و رعایت محدودیتهاست. در هر دو مثال، وزنهای شبکه به سمت مقادیر ثابتی همگرا شدهاند که نشاندهنده یادگیری موفق کنترلر است..
نتایج شبیه سازی با متلب را در زیر مشاهده می کنید.
نتایج مثال اول مقاله:

Fig. 2 Trajectories of the state x1, x2 and reference signal yr. (a) Tracking performance of system output, (b) Trajectory of the state x2.

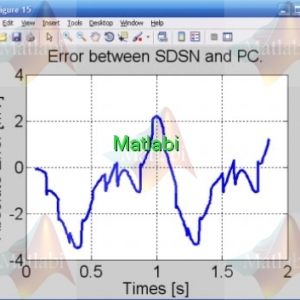
Fig. 3 Tracking errors. (a) Tracking error of transformed system. (b) Actual tracking of the original system.

Fig. 4 Control inputs. (a) Actual controller u(t), (b) Virtual controller ˆ α1

Fig. 5 Cost functions of the proposed scheme. (a) Cost function of subsystem 1, (b) Cost function of subsystem2.

Fig. 6 Weight of the neural networks. (a) ||Wˆc1||, (b) ||Wˆc2||, (c) ||Wˆa1||, (d) ||Wˆa2||, (e) ||Wˆf1||, (f) ||Wˆf2||,
نتایج مثال دوم مقاله:

Fig. 7 Tracking performance of system output x1

Fig. 8 System states. (a) State x2, (b) State x3.

Fig. 9 Actual tracking error of the original system

Fig. 10 Control inputs of the proposed scheme. (a) Actual control input u, (b) Virtual controller ˆ α1, (c) Virtual controller ˆ α2
همانطور که مشاهده می شوند نتایج به خوبی به دست آمده اند.
شاید به موارد زیر نیز علاقه مند باشید:
- Nonlinear control of a boost converter using a robust regression based reinforcement learning algorithm
- مدل کنترل پیش بین مبدل تقویت کننده DC/DC با یادگیری تقویتی
- کنترل و پایدارسازی بازوی مکانیکی روبات با استفاده از تئوری معادلات ریکارتی وابسته به حالت
- ادغام در مقیاس بزرگ تقاضا دفریبل و منابع انرژی تجدید پذیر
- شبیه سازی آماده مقالات IEEE
کلیدواژه:
Asymmetric time-varying full state constraints, Optimized backstepping, Nonlinear state-dependent function, Reinforcement learning
محدودیتهای حالت کامل متغیر با زمان نامتقارن, تابع وابسته به حالت غیرخطی, یادگیری تقویتی
کنترل بهینه مبتنی بر یادگیری تقویتی برای سیستم غیرخطی محدود از طریق یک تبدیل جدید وابسته به حالت با متلب
طبق توضیحات فوق توسط کارشناسان سایت متلبی تهیه شده است و به تعداد محدودی قابل فروش می باشد.
سفارش انجام پروژه مشابه
درصورتیکه این محصول دقیقا مطابق خواسته شما نمی باشد،.
با کلیک بر روی کلید زیر پروژه دلخواه خود را سفارش دهید.


دیدگاهها
هیچ دیدگاهی برای این محصول نوشته نشده است.