توضیحات
قانون هدایت تعاونی توزیعشده برای ازدحام پهپادها مبتنی بر یادگیری تقویتی
عنوان اصلی مقاله:
Distributed Cooperative Guidance Law for UAV Swarm Based on Reinforcement Learning
شبیه سازی در محیط ام فایل متلب انجام شده است.
دارای گزارش ورد 23 صفحه ای می باشد.
ترجمه چکیده مقاله:
این مقاله یک قانون هدایت تعاونی توزیعشده برای دسته پهپادهای بدون سرنشین (UAV Swarm) مبتنی بر الگوریتم یادگیری تقویتی عمیق تعیینگر چندعاملی (MADDPG) ارائه میکند. بهطور مشخص، ابتدا یک قانون هدایت تعاونی مبتنی بر سطح لغزشی (Sliding Surface) طراحی شده و سپس از نسخه بهبودیافته الگوریتم MADDPG برای طراحی هوشمند پارامترهای این قانون هدایت استفاده میشود. الگوریتم MADDPG بهبودیافته شامل یک ماژول ارتباطی مبتنی بر شبکه توجه چندسری (Multi-Head Attention Network) و همچنین یک شبکه Mixer است. نتایج شبیهسازی نشان میدهد که قانون هدایت پیشنهادی قادر است هدایت تعاونی و همکاری مؤثر میان دسته پهپادها را با موفقیت محقق سازد.
توضیحات الگوریتم بهبود یافته MADDPG برای سیستم چندعاملی در متلب
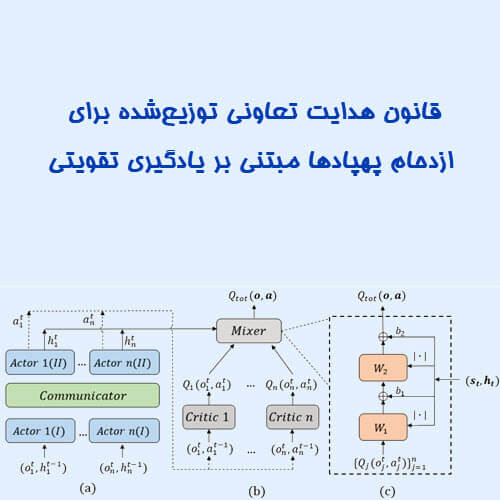
در این پروژه، پیاده سازی و شبیه سازی یک الگوریتم یادگیری تقویتی چندعاملی مبتنی بر نسخه بهبود یافته MADDPG در محیط MATLAB ارائه شده است. ساختار پروژه شامل شبکههای Actor، Critic و Mixer بوده و برای پردازش اطلاعات زمانی و ارتباط بین عاملها از GRU و مکانیزم Self-Attention استفاده شده است.
در این شبیه سازی، چند عامل در یک محیط سهبعدی تعریف شدهاند و الگوریتم با استفاده از یادگیری مبتنی بر Replay Buffer و شبکههای عصبی، فرآیند آموزش و بهینه سازی را انجام میدهد.
کد پروژه به صورت ماژولار طراحی شده و تقریباً تمامی بخشهای اصلی الگوریتم به صورت تابعی پیاده سازی شدهاند.
ویژگیهای پروژه
- پیاده سازی الگوریتم Improved MADDPG
- طراحی شبکه Actor مبتنی بر GRU
- استفاده از مکانیزم Self-Attention
- پیاده سازی شبکه Critic
- پیاده سازی شبکه Mixer
- طراحی Replay Buffer
- پیاده سازی Batch Sampling
- محاسبه Q-Value و Total Q-Value
- پیاده سازی تابع Loss
- بروزرسانی پارامترهای شبکهها
- مدیریت Hidden State ها
- رسم نمودارهای آموزشی
- پیاده سازی محیط چندعاملی سهبعدی
ساختار پروژه
شبکه Actor
در این پروژه، Actor با استفاده از:
- RNN
- GRU
- مکانیزم Self-Attention
پیاده سازی شده است.
شبکه Actor وظیفه تولید اکشن برای عاملها را برعهده دارد و خروجی آن بر اساس وضعیتهای مخفی GRU و پیامهای حاصل از Attention محاسبه میشود.
شبکه Critic
شبکه Critic برای تخمین Q-Value استفاده شده و شامل چند لایه Fully Connected است که ورودی آن ترکیبی از وضعیتها و اعمال عاملها میباشد.
شبکه Mixer
برای ترکیب Q-Value های محلی از Mixer Network استفاده شده است. این بخش مقدار Qtot را محاسبه میکند.
مکانیزم Self-Attention
در این پروژه، مکانیزم Attention شامل:
- Query
- Key
- Value
- Softmax
پیاده سازی شده و برای تبادل اطلاعات بین عاملها استفاده میشود.
بخشهای پیاده سازی شده
کد پروژه شامل پیاده سازی بخشهای زیر است:
- initializeActorParams
- initializeCriticParams
- initializeMixerParams
- initializeEnvironment
- initializeHiddenStates
- computeGRU
- gru_step
- computeSelfAttentionMessages
- attention_step
- actor_step
- executeActions
- computeRewards
- storeExperience
- sampleBatch
- computeQtot
- computeQValue
- computeMixerQValue
- computeLoss
- updateParameters
- updateHiddenStates
- checkTerminationCondition
توضیحات مهم پروژه
- در این پروژه تنها ساختار اصلی روش پیاده سازی شده است.
- برخی بخشها به صورت سادهسازی شده طراحی شدهاند.
- تابع پاداش بر اساس تفسیر و طراحی جایگزین پیاده سازی شده است.
- نتایج دقیقاً مشابه مقاله مرجع نیستند.
- برای نمایش بهتر روند آموزش، مقادیر پاداش مقیاسدهی شدهاند.
- گام زمانی به صورت متغیر نسبت به شماره اپیزود تغییر میکند تا دقت آموزش افزایش پیدا کند.
- بروزرسانی پارامترها به صورت سادهسازی شده انجام شده است.
- از گرادیانگیری دستی ساده برای بروزرسانی استفاده شده و پیاده سازی مبتنی بر فریمورکهای Deep Learning نیست.
خروجیهای پروژه
- کد کامل MATLAB
- شبیه سازی سیستم چندعاملی
- نمودار میانگین پاداش
- نمودار واریانس پاداش
- نمودار تعداد گامها
- ساختار کامل Actor / Critic / Mixer
- پیاده سازی Replay Buffer
- پیاده سازی مکانیزم Attention
- پیاده سازی GRU
نتایج بدست آمده از شبیه سازی با متلب:
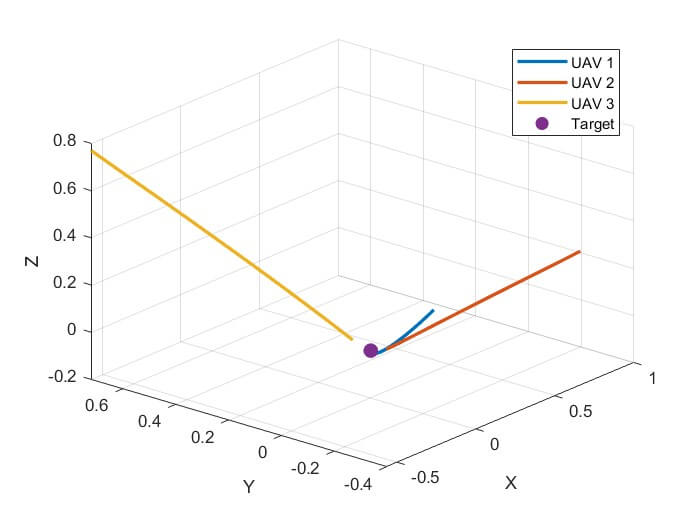
Fig. 4. Flight Trajectory produced by CPG
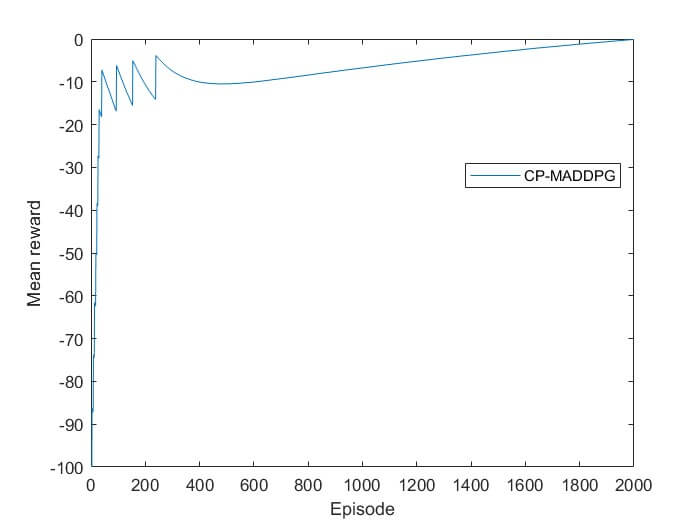
Fig. 5. Flight Trajectory produced by CP-MADDPG
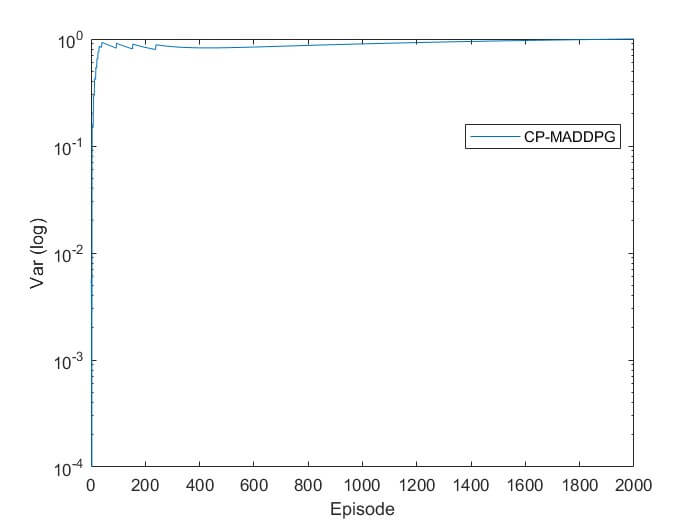
fig 6: Rewards
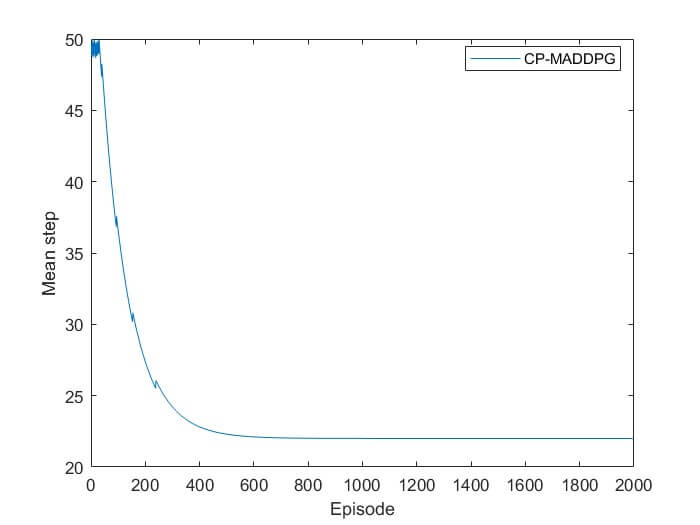
Average Step Length
کاربردهای پروژه
این پروژه مناسب موارد زیر است:
- تحقیق در یادگیری تقویتی
- آشنایی با MADDPG
- آموزش سیستمهای چندعاملی
- توسعه الگوریتمهای RL
- تحقیقات Deep Reinforcement Learning
- آموزش مکانیزم Attention
- آموزش GRU در متلب
تکنیکهای استفاده شده
| بخش | تکنیک |
|---|---|
| یادگیری تقویتی | MADDPG |
| شبکه بازگشتی | GRU |
| مکانیزم توجه | Self-Attention |
| شبکه ترکیب | Mixer Network |
| یادگیری چندعاملی | Multi-Agent RL |
| حافظه تجربیات | Replay Buffer |
| تخمین ارزش | Q-Value |
| آموزش شبکه | Gradient Update |
محیط پیاده سازی
- MATLAB
- برنامه نویسی تابعمحور
- پیاده سازی ساختاریافته
- قابلیت توسعه و شخصی سازی
مناسب برای
- مهندسی برق
- مهندسی کنترل
- هوش مصنوعی
- رباتیک
- پژوهشگران یادگیری تقویتی
- علاقهمندان سیستمهای چندعاملی
شاید به موارد زیر نیز علاقه مند باشید:
- کنترل پیشبین مدل خروجی–بازخورد توزیعشده مقاوم مبتنی بر رویداد برای سامانههای چندعاملی غیرخطی در برابر حملات تزریق داده جعلی
- کنترل مشارکتی بهینه با استفاده از یادگیری تقویتی ساده شده برای دسته ای از سیستم های چند عاملی با دینامیک ناشناخته
- کنترل بهینه مبتنی بر یادگیری تقویتی برای سیستم غیرخطی محدود از طریق یک تبدیل جدید وابسته به حالت
- کنترل تطبیقی شبکه عصبی برای سامانههای یکپارچه هدایت و کنترل مبتنی بر ناظر اغتشاش
- مدل کنترل پیش بین مبدل تقویت کننده DC/DC با یادگیری تقویتی
شبیهسازی قانون هدایت همکاری توزیعشده برای دسته پهپادها با استفاده از یادگیری تقویتی چندعاملی در متلب
طبق توضیحات فوق توسط کارشناسان سایت متلبی تهیه شده است و به تعداد محدودی قابل فروش می باشد.
سفارش انجام پروژه مشابه
درصورتیکه این محصول دقیقا مطابق خواسته شما نمی باشد،.
با کلیک بر روی کلید زیر پروژه دلخواه خود را سفارش دهید.

دیدگاهها
هیچ دیدگاهی برای این محصول نوشته نشده است.